On CSS Forgiveness
Published onOne of the main features of the CSS language (and of HTML) is that it handles errors gracefully. It is said that browsers ignore any CSS they don't understand.
But not all errors in CSS are handled in the same way. In some cases, the browser ignores more or less than what
we would expect. For example, the recently introduced :is() and :where() selectors are forgiving, while
:has() ended up being unforgiving. But what
does this mean? Let's dig into the details of CSS error handling.
CSS Syntax
Let's start by looking at the basics. CSS is a simple (but not easy) language. We can sum up most of the language syntax in a simple picture:
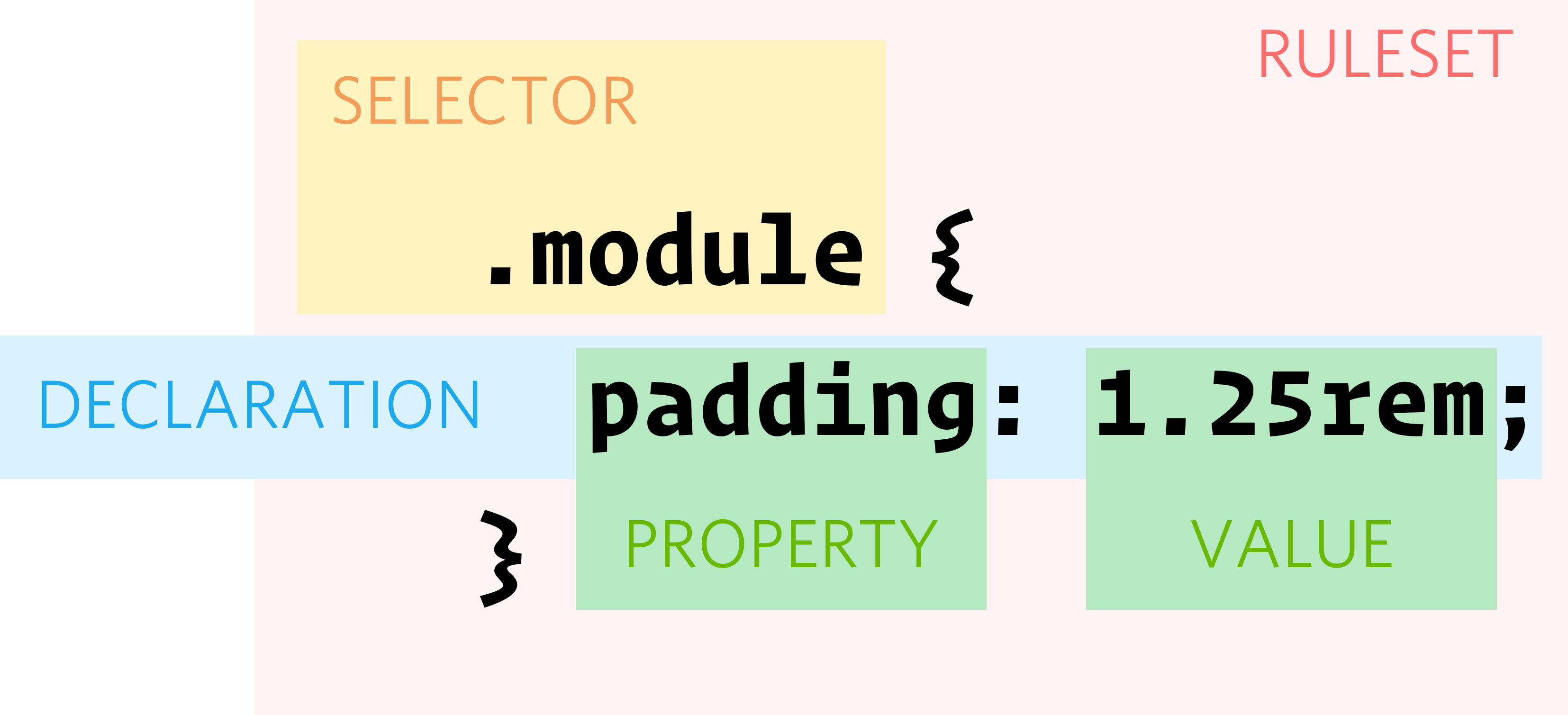
There are statements which can be at-rules (not in the diagram above) or rulesets. Rulesets
are composed by selector (lists) and declarations. Declarations are made up of
properties and values. You can find more details about the CSS syntax in MDN
So, when we say that a browser doesn't understand some CSS, it can be one of 2 things:
- Syntax errors: something that doesn't quite look like the diagram
- Unknown tokens (selectors, properties, values): It looks correct but the browser doesn't understand it.
Syntax errors
These are the kind of errors we don't make on purpose. With modern code editors and tools we can avoid them most of the time, but it's easy to forget a semicolon, for example.
In general, browsers will recover from syntax errors trying not to break much. If it's just a missing semicolon, only a couple of declarations get broken, which is great. Of course, depending on the error, it might get much worse.
Let's looks at the other kind of "errors", which are much more interesting.
CSS forgiveness
We can write CSS taking advantage of the way errors are handled. Let's look at how CSS works when it doesn't understand syntactically correct code.
Declarations
When it comes to declaration, any properties or values that the browser doesn't recognize are ignored. The browser only ignores the invalid declaration, but other declarations in the ruleset work fine. This allows us to try out new values or properties that are not widely supported yet.
This is perhaps the most common technique that takes advantage of CSS forgiveness. We just write a declaration twice: One for the fallback, using widely supported CSS and on the next line we use newer CSS that overrides the first declaration, or is just ignored if the browser doesn't understand it. Here's an example taken from https://web.dev/learn/css/the-cascade/#position-and-order-of-appearance
.my-element {
font-size: 1.5rem;
font-size: clamp(1.5rem, 1rem + 3vw, 2rem);
}If the browser supports clamp it will apply the second statement, otherwise it will just ignore it.
Selectors
Normally, when there's an error in a selector, the whole selector group (or list) is consider invalid and the ruleset is ignored. However there are 2 exceptions to this rule:Forgiving selector parsing
:is() and :where() are pseudo-classes that accept
forgiving selector lists.
This means that if any of the selectors in the list is invalid, only that selector is ignored, instead of the whole list.
Let's look at the following
article:has(footer, ::-crap) { ... }
:is(header, ::-crap) { ... }The selector list in :has is not forgiving, so the invalid ::-crap makes browser ignore the whole ruleset.
On the other hand, the second ruleset works fine. Only ::-crap is ignored. It would be equivalent to:
:is(header) { ... }-webkit- pseudo-elements
Any webkit prefixed pseudo-element, is accepted as valid, even if it doesn't exist. So ::-webkit-blah would be
accepted. If the browser doesn't know how to handle it, it's ignored and the rest of the selector list works fine.
We can say that invalid -webkit- pseudo-elements are always forgiven by the CSS parser.
The reason for this is that back in the day browsers experimented with new features by using vendor prefixes, which ended up all over the place, and people used them without much care. This resulted in some websites that only worked for Chrome, or other Webkit based browsers. Firefox had to add this exception to the Gecko engine and now it's part of the CSS spec.
At-rules
An at-rule begins with an at-keyword, like @import, and can followed by some values. Some of them, called
block at-rules, are then followed by a { } block of statements or declarations, like in the
case of @media and @font-face.
Each at-rule has its own syntax, but in general any unrecognized at-keyword or value causes the whole statement to be ignored. This is similar to how errors are handled for selector lists.
Conditional at-rules
We can think of an exception to the rule above for conditional at-rules, which are @media and
@supports. These at-rules take one or more conditions separated by logical operators. If one of the conditions has
an unrecognized value, only that condition is evaluated as false. So we can have something like this:
@media (min-height: 20lh) or (min-height: 20em) {
font-size: 2em;
}
If the browser doesn't understand the lh unit, it will only return false to the first condition,
but the whole condition won't be ignored, and since the or operator is used, the font-size: 2em will be applied
when the second condition is met.
Summing up
This was a great opportunity to revisit the CSS syntax, terminology and admire the amazing design of the language, that has manage to keep its simplicity even with the amount of powerful features that have been added in recent years.
Nowadays it's pretty easy to write error-free CSS code, but we can also take advantage of the forgiving nature of the language to try out new functionality in a clean and safe way. This is what Progressive Enhancement is all about.